F2FS: Hệ thống tập tin mới cho Flash Storage (Phần 1)
Review paper F2FS - hệ thống tập tin tối ưu cho flash storage, phân tích thiết kế multi-head logging và adaptive logging.
1. Lời nói đầu
Trước tiên, F2FS cũng không phải là hệ thống tập tin mới, đến nay đã hơn 10 năm rồi, nhưng điều đó không cản trở sự phổ biến của nó trong lĩnh vực thiết bị flash. Sau đó, thực ra tôi không thực sự đọc paper, mà là nghe bài thuyết trình của tác giả, cũng không ai quy định paper nhất định phải đọc chữ đúng không.
2. Background: Tại sao cần F2FS?
Lý do chính là random write không có lợi cho thiết bị flash. Random write có hiệu suất thấp hơn sequential write là điều thường thức rồi, nhưng còn có một lý do khác là ảnh hưởng đến tuổi thọ thiết bị, điều này được quyết định bởi đặc tính vật lý của flash - nhược điểm cần FTL hoàn thành thao tác erase-before-write, random write chính là khuếch đại nhược điểm này.
Suy nghĩ sâu hơn là cần làm một hệ thống tập tin hướng đến sequential write (có đặc tính wear leveling), và đó chính là F2FS.
3. Tư tưởng thiết kế và đặc tính chính
- Flash-friendly on-disk layout.
- Cost-effective index structure.
- Multi-head logging.
- Adaptive logging.
- fsync() acceleration with roll-forward recovery.
4. Layout
Thế nào mới được coi là bố cục đĩa cứng thân thiện với flash?
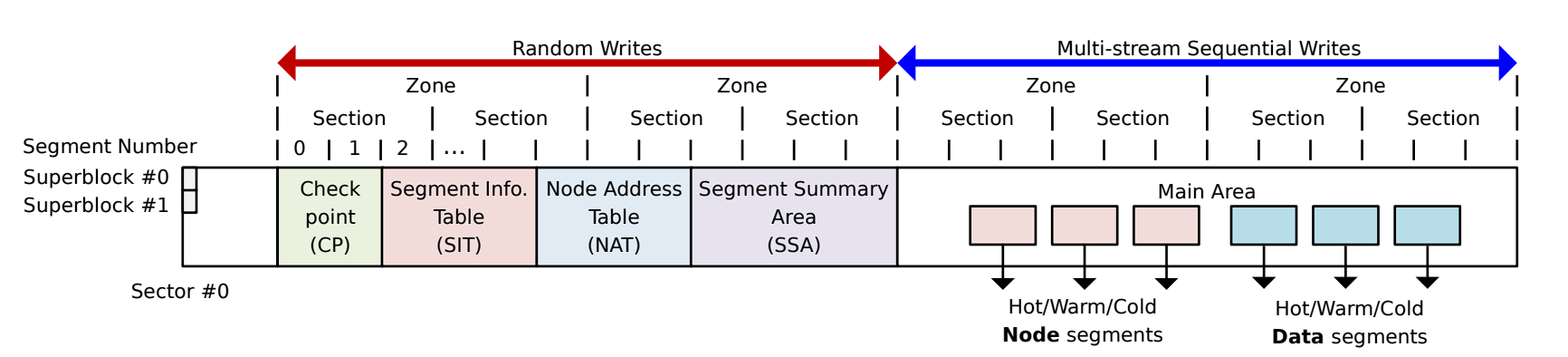
Câu trả lời của tác giả là bố cục như hình trên là thân thiện: nó xem xét đến flash awareness và clean cost reduction.
Flash awareness có nghĩa là hệ thống tập tin khớp với đặc tính vật lý của flash:
- superblock metadata được lưu trữ cùng nhau (và ở đầu), để cải thiện locality và parallelism.
- main area có địa chỉ bắt đầu được align với kích thước zone, điều này xem xét đến đặc điểm hoạt động của FTL.
- GC của hệ thống tập tin theo đơn vị section.
Clean cost reduction thì sử dụng Multi-head logging để thực hiện phân tách dữ liệu nóng lạnh, xem Hot / Warm / Cold trong hình.
Bổ sung một số giải thích về bố cục đĩa cứng, phần sau đây từ kernel tài liệu:
- F2FS chia toàn bộ volume thành nhiều segment, mỗi segment có kích thước 2MB.
- F2FS phân chia theo ba cấp: section chứa nhiều segment, zone chứa nhiều section, nhưng mặc định là quan hệ 1:1:1.
- F2FS phân chia chức năng thành 6 area: từ super block đến main như hình minh họa.
- Như đã nói ở trên, main area align theo zone, đồng thời check point align theo segment.
- Ngoại trừ super block, các area khác đều có nhiều segment.
6 area này lưu trữ thông tin sau:
- Superblock: Thông tin phân vùng cơ bản và tham số mặc định của F2FS. Nó có 2 bản backup để tránh crash hệ thống tập tin.
- CP: Thông tin hệ thống tập tin, bitmap của NAT/SIT, orphan inode, và summary entry của active segment.
- SIT: Thông tin segment, như số lượng valid block, valid bitmap tương ứng với block (của main area).
- NAT: Map địa chỉ của tất cả node block trong main area.
- SSA: Summary entry, ở đây chỉ mối quan hệ thuộc về tương ứng với block trong main area (parent node / offset, v.v.).
- Main area: Thông tin file và directory, cũng như thông tin index của chúng.
Ở đây có một câu hỏi: tại sao cần phân chia ba cấp (zone-section-segment)? Hiểu biết cá nhân của tôi là zone được đưa vào là xem xét đến đơn vị hỗ trợ FTL nhận diện dữ liệu nóng lạnh (xem phần Multi-head logging bên dưới); còn section thì là một đơn vị được chọn khi GC hệ thống tập tin (performs “cleaning” in the unit of section. …identify a victim selection, xem phần Cleaning bên dưới); còn segment là đơn vị quản lý cơ bản (allocates storage blocks in the unit of segments), điều này có thể là do F2FS vẫn là hệ thống tập tin thiết bị khối để thích ứng; việc chọn kích thước của cả ba đơn vị này đều cần xem xét đặc điểm phần cứng FTL.
5. Index structure
Tác giả thể hiện ưu thế hiệu quả index của F2FS thông qua so sánh với LFS:
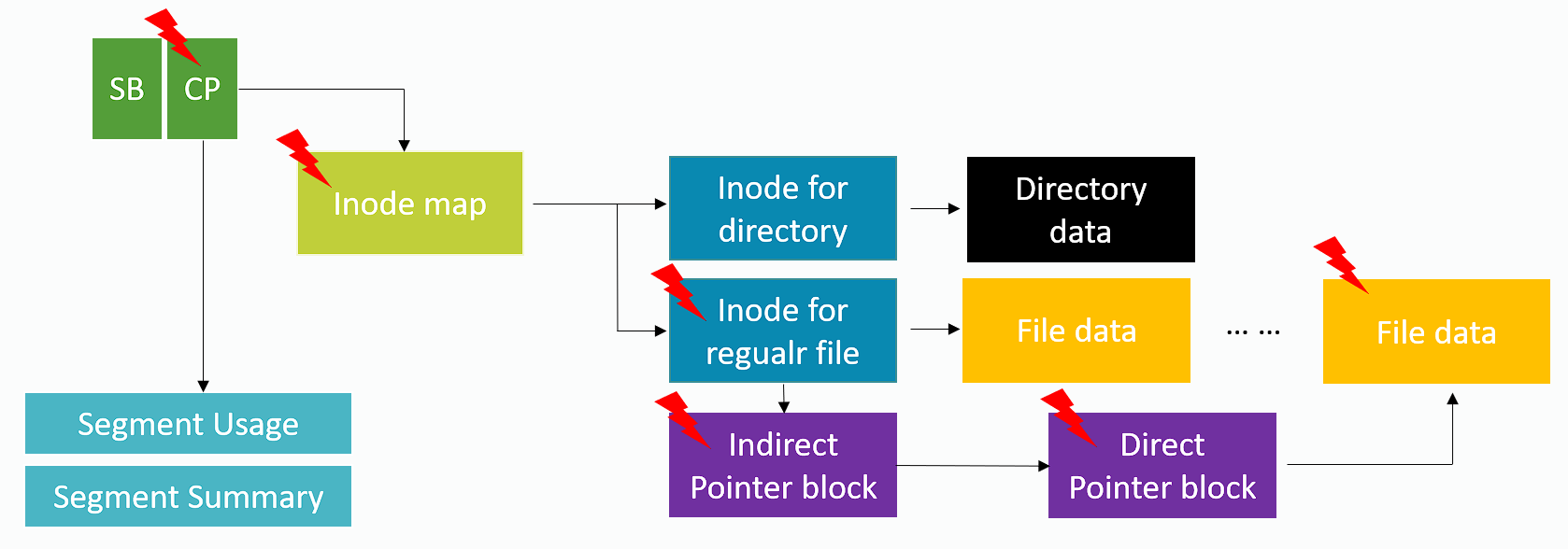 LFS
LFS
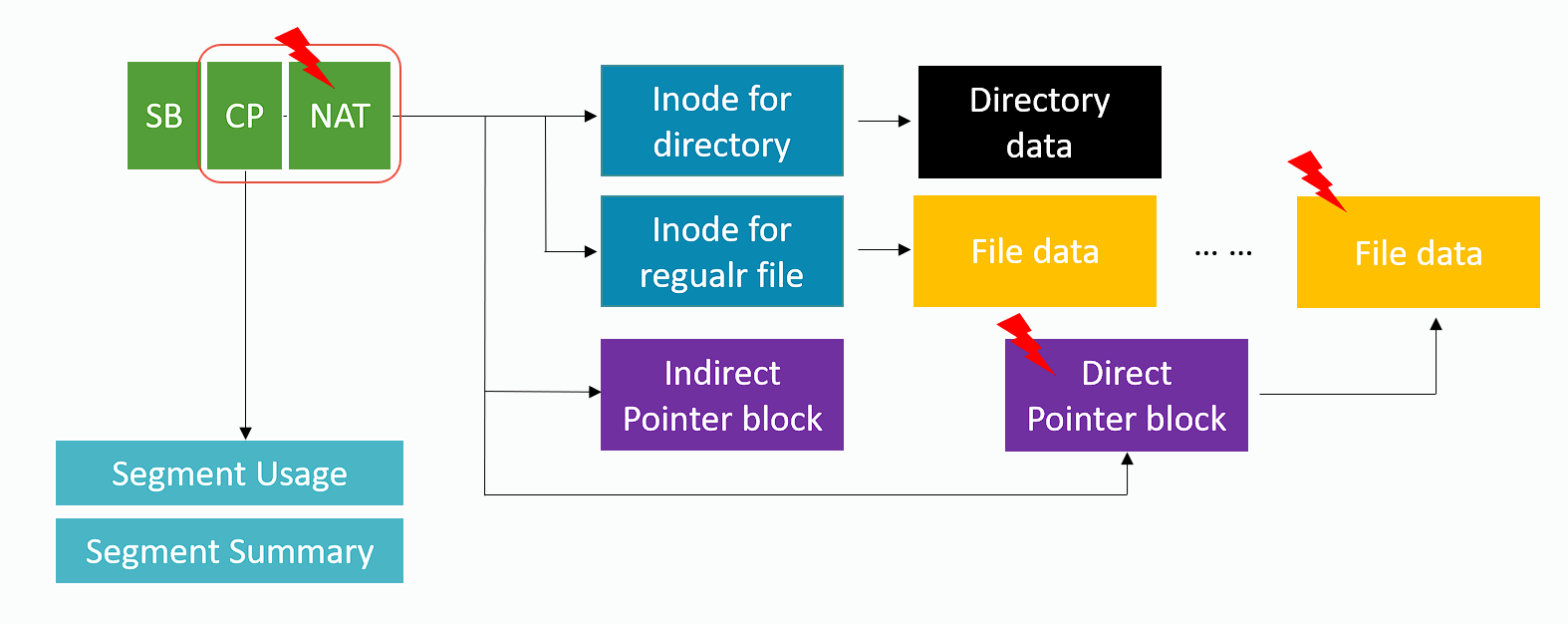 F2FS
F2FS
1
2
* SB = super block
* CP = check point
Tác giả chỉ ra LFS có 2 vấn đề:
- Update propagation (Wandering tree): Ngay cả khi chỉ muốn update một block, bên trong cũng cần update thêm nhiều intermediate block (xem dấu ⚡ màu đỏ).
- One big log: Không quan tâm gì cũng đi vào cùng một log, không phân biệt đặc điểm của block.
Còn F2FS thì giải quyết từng vấn đề:
- Sử dụng NAT (node address table) để xử lý wandering tree: Thông qua một bảng lớn để trực tiếp dịch node block id sang địa chỉ vật lý, tránh truy cập indirect pointer block. Trong scenario ở hình trên, không cần update inode và indirect pointer block (vì indirect pointer block ghi node id, còn direct pointer block ghi block address).
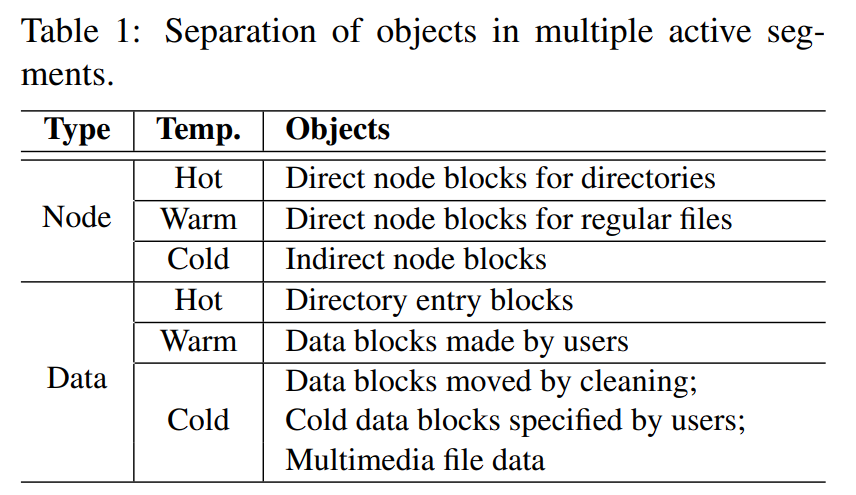
- Sử dụng multi-head log để thay thế one big log: Xem bảng trên, phân theo loại và nhiệt độ thành 6 loại log. Phân biệt node và data là vì tần suất update của node cao hơn data; hai loại này bên trong cũng phân nhỏ nhiệt độ khác nhau, một số nguyên tắc là direct nóng hơn indirect, dentry nóng hơn user file.
Ngoài ra trong chia sẻ LWN thời kỳ đầu cũng đề cập đến tư tưởng phân tách này, tóm lại là nó có hai lợi ích: một là tầng hệ thống tập tin, log đủ lạnh có thể tránh section GC không cần thiết; hai là tầng phần cứng, một thiết bị phần cứng có thể được cấu thành từ nhiều thiết bị con, phân tách (và sau khi điều chỉnh tham số zone hợp lý) có thể nâng cao mức độ song song của IO.
6. Multi-head logging
Ở trên đã đề cập đến tư tưởng phân tách nóng lạnh của Multi-head logging, còn tác giả ở 8:06 đối với multiple log vẫn có bổ sung, nhưng tôi không nghe rõ thái độ cụ thể của tác giả, có vẻ như đang thảo luận về mối liên hệ giữa việc phân tách nóng lạnh này với FTL ở tầng phần cứng: dù có multiple log, nhưng FTL mapping không thể biết được mối quan hệ này, dù F2FS phân tách nóng lạnh, cuối cùng FTL mapping vẫn trộn lẫn trong cùng một erase block để lưu trữ, hiện tượng node block và data block trộn lẫn này được gọi là zone-blind allocation.
Tác giả giả định F2FS là zone-based mapping, FTL sẽ đặt các log khác nhau vào các khu vực khác nhau. Tôi nghĩ ý nghĩa ở đây là độ chi tiết phân tách dữ liệu phải theo zone để phân chia, như vậy mới tránh được việc FTL mapping sau đó dẫn đến trộn lẫn.
7. Cleaning
Bí quyết tăng tốc GC là section align theo kích thước đơn vị FTL GC. Nói đơn giản là tránh sự không nhất quán giữa hệ thống tập tin và tầng FTL, thực ra cũng không có gì để nói, hệ thống tập tin sẽ làm GC để dọn dẹp dữ liệu, nhưng FTL có thể sẽ giữ lại, không align thì là hai tầng không phối hợp gây lãng phí hiệu suất.

Quy trình cụ thể như hình, cleaning có thể thực thi ở foreground (hiệu quả tham lam), cũng có thể thực thi ở background (chi phí tối ưu):
- Tham lam và tối ưu chỉ chiến lược thuật toán tìm victim section.
- Thuật toán tham lam cố gắng tìm section chứa ít valid block nhất, thông qua kiểm soát chi phí di chuyển block để giảm độ trễ foreground.
- Thuật toán tối ưu ngoài xem xét tỷ lệ sử dụng như tham lam, còn cần tham khảo mức độ “lão hóa” (age) của section.
SIT sẽ ghi thời điểm last modified, và giá trị trung bình của thời gian này chính là “tuổi” của một section.
8. Adaptive logging
Còn cleaning sẽ tốn nhiều thời gian hơn khi lão hóa (chiếm dụng cao, nhiều phân mảnh), để giảm chi phí đã đưa vào adaptive logging. Nói cụ thể, là trong các trường hợp khác nhau sử dụng chiến lược ghi khác nhau:
- Khi hệ thống tập tin chỉ còn 5% free section, sử dụng threaded logging.
- Nếu không thì sử dụng append logging.
- Đối với node, không quan tâm kích thước không gian luôn sử dụng append logging.
threaded logging là tái sử dụng segment đã ghi, do đó là hành vi random write, nhưng không cần thao tác cleaning; còn append tuy là hành vi sequential write, nhưng khi không gian không đủ vẫn cần cleaning, lúc này sẽ là hành vi random write nghiêm trọng hơn. Đây cũng là lý do tại sao sử dụng chiến lược ghi động.
9. Recovery
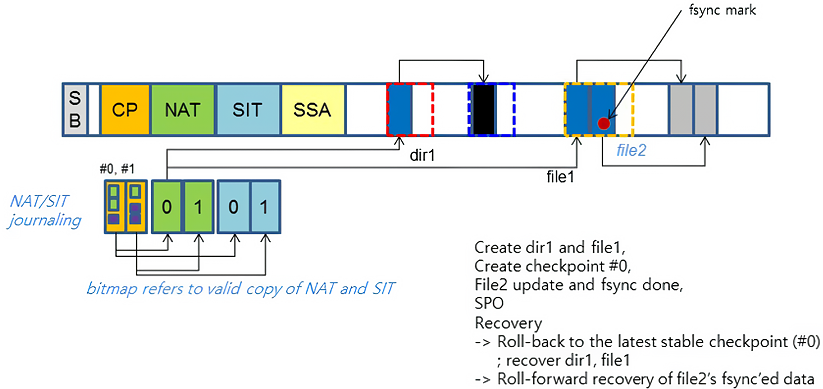
1
* SPO = Sudden Power Off
F2FS sử dụng check point để thực hiện tính nhất quán của hệ thống tập tin, tránh crash dẫn đến hỏng hệ thống tập tin. Khi gọi sync(), umount() hoặc foreground GC, F2FS sẽ trigger check point. Nói đơn giản, check point là một loại shadow copy (backup không được user cảm nhận), backup của nó sẽ được đặt xen kẽ ở phần #1 và #0 của CP area, nội dung check point bao gồm NAT/SIT journaling, tránh ghi trực tiếp vào NAT/SIT block.
Sau khi cung cấp thông tin cần thiết, để thực hiện recovery là lấy check point mới nhất, rồi roll-back recovery về thời điểm tương ứng.

Tuy sử dụng check point để thực hiện fsync() là một tư tưởng khả thi, nhưng chi phí là khá cao. Để giảm chi phí thực thi fsync(), F2FS còn đưa vào thao tác roll-forward recovery để thay thế thao tác roll-back của check point. Tư tưởng của nó là chỉ update direct node block và data block tương ứng (trong đó direct node block được đánh dấu FSYNC). Khi thực hiện recovery, thông qua block đã đánh dấu để làm lại một lần thao tác ghi.
10. Benchmark
Phần benchmark chủ yếu so sánh với ext4, kết luận workload sơ bộ như sau:
- Theo thiết bị: SATA SSD có cải thiện 2.5 lần, PCIe SSD có cải thiện 1.8 lần.
- Theo ứng dụng: SQLite có cải thiện 2 lần, iozone có cải thiện 3.1 lần.
Nhưng những dữ liệu này cách thời điểm hiện tại khá xa, giá trị tham khảo không cao (bạn cũng có thể lấy dữ liệu mới hơn tại đây). Những năm gần đây theo kinh nghiệm của công ty cũ, thiết bị di động trong các trường hợp khác nhau với ext4 có thắng có thua.
Ngoài ra tác giả trong bài thuyết trình cũng ám chỉ, F2FS mạnh như vậy là vì nó rất hiểu đặc điểm của FTL (thậm chí có thể dùng một loại stream interface để điều khiển hành vi của FTL). Tại sao hiểu? Vì tác giả là nhân viên Samsung, còn FTL của thiết bị test chính là do Samsung tự làm, làm sao không hiểu được? Điều này cũng có nghĩa là bạn đặt vào thiết bị của nhà sản xuất khác với firmware khác, chưa chắc đạt được khoảng cách điểm số khoa trương như trên.
Tóm lại, dù bạn dùng code open source có vẻ giống hệt nhau, giữa tự nghiên cứu và không tự nghiên cứu, thực chất tồn tại một bức tường cao.
11. Tài liệu tham khảo
FAST ‘15 - F2FS: A New File System for Flash Storage - YouTube