IO: Cơ chế blk-mq (Block IO Layer Multi-Queue) trong nhân Linux (Phần 2)
Phân tích cơ chế blk-mq multi-queue trong Linux kernel, từ kiến trúc framework đến luồng xử lý IO cho thiết bị NVMe.
1. Giới thiệu
Bài viết này trước tiên sẽ giới thiệu ngắn gọn về framework blk-mq từ góc độ bối cảnh và kiến trúc, sau đó sẽ đi sâu hơn vào cơ chế triển khai nội bộ thông qua cấu trúc dữ liệu và các luồng cụ thể.
2. Bối cảnh
2.1. blk-mq là gì?
The Multi-Queue Block IO Queueing Mechanism is an API to enable fast storage devices to achieve a huge number of input/output operations per second (IOPS) through queueing and submitting IO requests to block devices simultaneously, benefiting from the parallelism offered by modern storage devices.
TL;DR blk-mq là framework multi-queue IO của block layer trong kernel, phù hợp với các thiết bị lưu trữ multi-queue có yêu cầu IOPS cao.
2.2. Tại sao cần blk-mq?
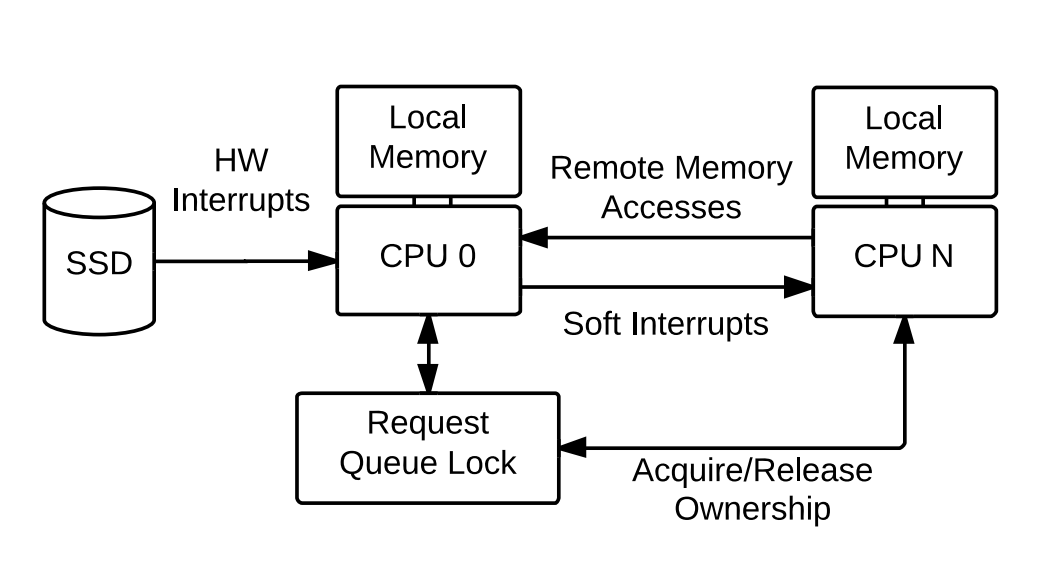 Software bottleneck
Software bottleneck
Lý do chính là sự phát triển của multi-core và multi-queue, khiến bottleneck hiệu suất chuyển từ phần cứng sang phần mềm: single-queue framework gặp vấn đề về lock contention và remote memory access. Do đó, việc tái cấu trúc là cần thiết.
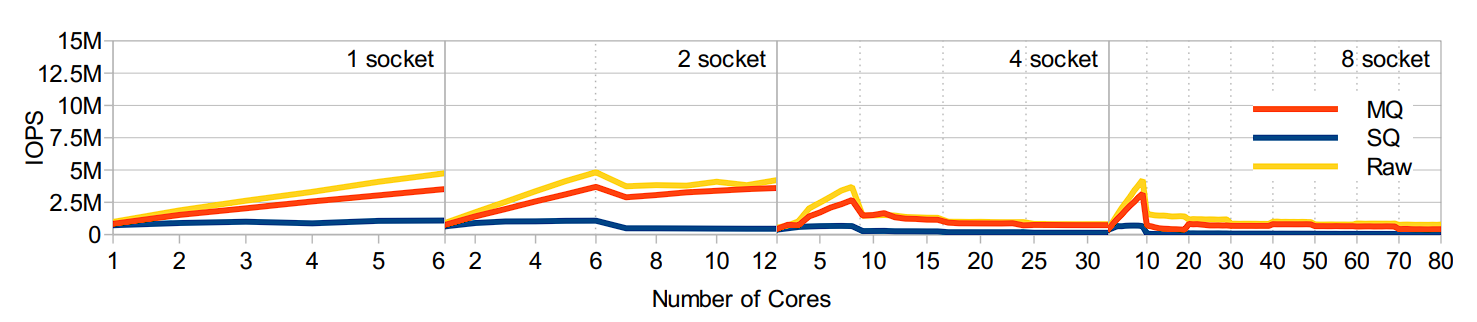
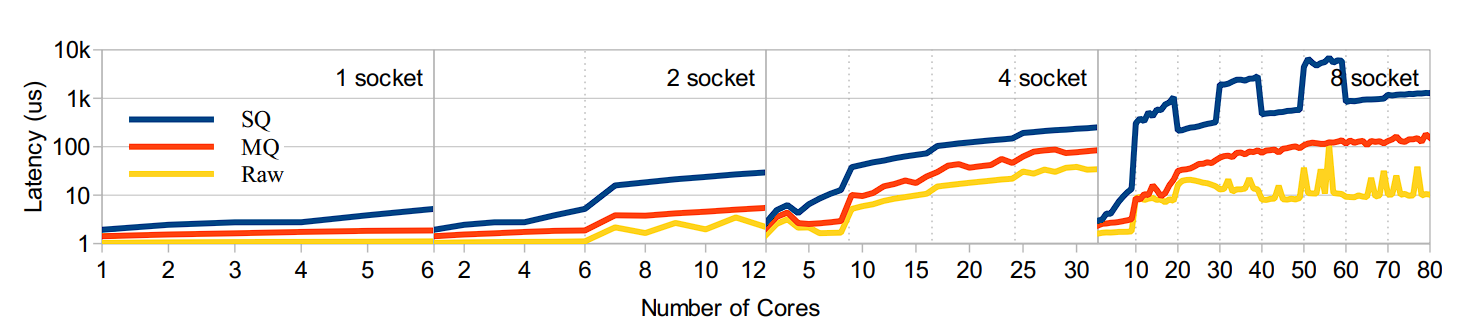
Trong benchmark cụ thể, có thể thấy single-queue framework (SQ) không thể đáp ứng được sự phát triển của phần cứng về mặt khả năng mở rộng.
3. Tổng quan Framework
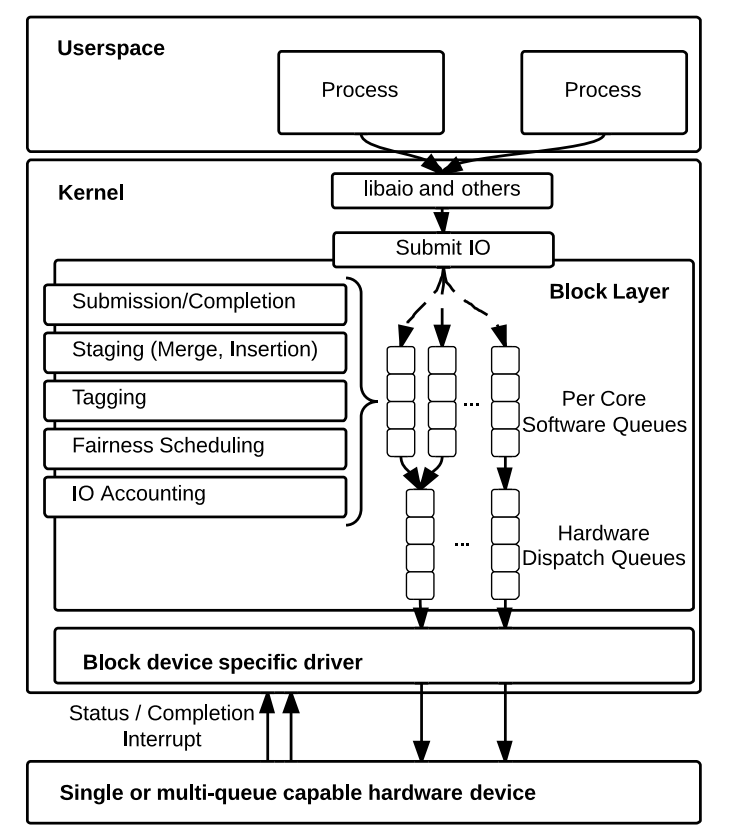
Để giảm lock contention và tận dụng tối đa locality principle, blk-mq tách single queue vừa chịu trách nhiệm submit vừa dispatch thành multi-level và multi-queue.
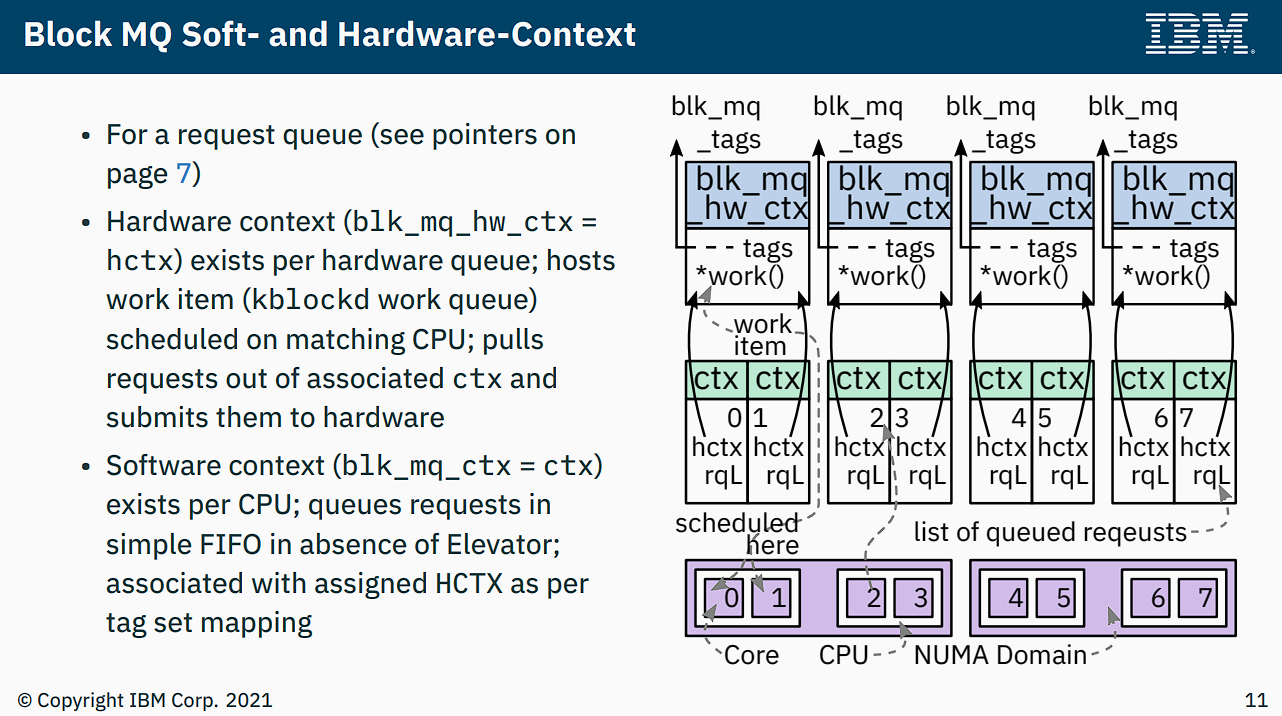
Framework blk-mq có 2 loại queue:
- Software Staging Queue cấp per-cpu
- Thường được gọi là software queue, software staging queue, ctx (context)
- Tương ứng với cấu trúc dữ liệu
blk_mq_ctx
- Hardware Dispatch Queue tương ứng với hardware queue của thiết bị lưu trữ
- Thường có các tên gọi kỳ lạ như hardware queue, hctx (hardware context), hwq
- Tương ứng với cấu trúc dữ liệu
blk_mq_hw_ctx - Request vào queue này có nghĩa là đã được scheduling
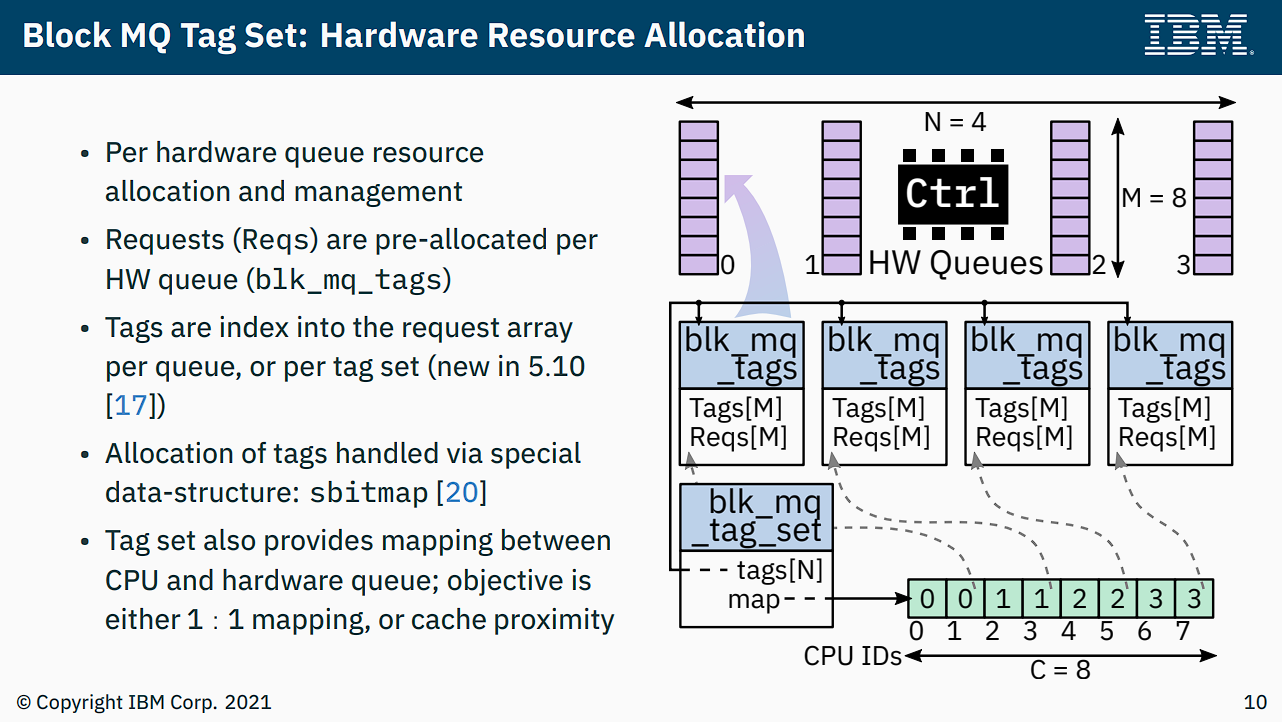
Mỗi thiết bị lưu trữ có một controlling structure là blk_mq_tag_set, dùng để duy trì mối quan hệ giữa các queue:
- Field:
.mq_maps- Type:
int*, thực tế sử dụng như arrayint[]với độ dài bằng số CPU - Purpose: Thực hiện mapping từ CPU đến hardware queue
- Note: Index là CPU number, giá trị tương ứng là hardware queue number được map. Ví dụ
set->mq_map[cpu_j] = hw_queue_i, trong đó i và j không liên quan
- Type:
- Field:
.tags- Type:
blk_mq_tags**, thực tế sử dụng như array(blk_mq_tags*)[]với độ dài bằng số CPU - Purpose: Quản lý phân bổ request, phân bổ
set->tags[hw_queue_id]cho mỗi hwq
- Type:
Hardware queue được liên kết với tag (từ đó gián tiếp liên kết với request), cấu trúc tương ứng là blk_mq_tags:
- Field:
.static_rqs- Type:
request**, thực tế sử dụng như array(request*)[]với độ dài bằng queue depth parameterset->queue_depth - Purpose: Pre-allocate
set->queue_depthrequest instances từ buddy, chờ sử dụng sau này - Note: Array này cần tag allocation, sử dụng bitmap (sbitmap) đi kèm để nhanh chóng lấy free tag. Mỗi lần dispatch request trước tiên cần lấy tag để bind
- Type:
- Field:
.rqs- Type:
request**, thực tế sử dụng như array(request*)[]với độ dài bằng queue depth parameterset->queue_depth - Purpose: Request instance lấy từ
static_rqs[tag]trong non-elevator scheduling sẽ được đặt vào array này (cùng index), biểu thị in-flight request - Note: Thực tế tôi không biết để làm gì, một khả năng là cung cấp iterator cho driver để duyệt tất cả request đang sử dụng
- Type:
Mối quan hệ giữa tag-set và ctx có thể xem trong hình dưới:
4. Khởi tạo Framework
4.1. Luồng nvme_probe
Framework blk-mq hoàn thành khởi tạo ở driver layer, lấy nvme device làm ví dụ, giai đoạn khởi tạo chia thành upper và lower half. Upper half bắt đầu từ function nvme_probe:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
nvme_probe(...)
dev = kzalloc_node(...)
...
INIT_WORK(..., nvme_reset_work)
// Trong async flow
nvme_reset_work(work)
dev = container_of(work, ...)
...
nvme_dev_add(dev)
...
nvme_dev_add(dev)
dev->tagset.ops = nvme_mq_ops
dev->tagset.nr_hw_queues = ...
// Số hwq cuối cùng sẽ bị giới hạn đến min(số hardware queue, số CPU)
dev->tagset.queue_depth = min(dev->q_dep, 10240) - 1
// Ở đây queue depth của tagset chưa được xác định cuối cùng, nếu quá trình construct sau này thất bại,
// kernel sẽ thử giảm depth một nửa và retry, cho đến khi depth chỉ còn 1
dev->tagset.flags = BLK_MQ_F_SHOULD_MERGE
blk_mq_alloc_tag_set(alias set = dev->tagset)
set->tags = kcalloc_node(nr_cpu_ids, sizeof *, ...)
// Ở đây cho thấy tags là array với element type là blk_mq_tags*, length là số CPU
set->mq_map = kcalloc_node(nr_cpu_ids, sizeof, ...)
// mq_map là array với element type là int, length là số CPU
blk_mq_update_queue_map(set)
// Quá trình này hoàn thành mapping từ CPU đến hw queue
for-each cpu: set->mq_map[cpu] = 0
set->ops->map_queues(ret)
// Tương ứng với implementation nvme_pci_map_queues
for-each hwq: for-each cpu-in-mask: set->mq_map[cpu] = queue
blk_mq_alloc_rq_maps(set)
// Construct set->tags[0...hctx_max-1]
// Bỏ qua trường hợp đặc biệt depth giảm một nửa
for-each hwq, i: __blk_mq_alloc_rq_map(set, alias hctx_idx = i)
// Construct set->tags[hctx_idx]
set->tags[hctx_idx] = blk_mq_alloc_rq_map(set, hctx_id, ...)
// Lấy numa_node node
// Định nghĩa (tương ứng queue) tags = blk_mq_init_tags(...)
// Xác nhận tags->nr_tags và tags_nr_reserved_tags
// cũng như construct sbitmap
tags->rqs = kcalloc_node(nr_tags, sizeof *)
// rqs là array với element type là request* với length là queue depth
tags->static_rqs = kcalloc_node(nr_tags, sizeof *)
return tags
blk_mq_alloc_rqs(set, set->tags[hctx_id], hctx_id, queue_depth)
// Construct tags->page_list, theo queue depth d nhân request size có payload với d,
// allocate page tương ứng từ buddy, và sử dụng virtual address của page
// lưu vào static_rqs[...], trong đó nhiều page có thể traverse qua page_list
// Sau khi allocate request, có thể từ set->ops->init_request custom initialize request
dev->ctrl.tagset = dev->tagset
4.2. Luồng nvme_alloc_ns
Lower half có caller call stack như sau:
1
2
3
4
5
nvme_alloc_ns
nvme_validate_ns
nvme_scan_ns_list
nvme_scan_work(async)
nvme_init_ctrl
Trong đó, nvme_init_ctrl sử dụng workqueue để async trigger nvme_scan_work.
1
2
3
4
5
6
7
8
9
10
11
12
nvme_alloc_ns(ctrl, nsid)
nvme_ns *ns = kzalloc_node(...)
ns->queue = blk_mq_init_queue(ctrl->tagset) ⭐
ns->queue->queuedata = ns
ns->ctrl = ctrl
...
disk = alloc_disk_node(...)
disk->fops = nvme_fops
disk->private_data = ns
disk->queue = ns->queue
ns->disk = disk
...
Có thể thấy ở đây chính thức vào framework blk-mq, và tagset đã construct ở upper half cũng được truyền vào framework. Ngoài ra, gendisk cũng thiết lập association với nvme, phần liên quan đến blk-mq là disk->queue đến từ ns và được construct qua framework blk-mq.
4.3. Luồng blk_mq_init_queue
Luồng này là initialization flow của request_queue, liên quan đến ctx và hctx được bind với nó.
blk_mq_init_queue(set)
q = blk_alloc_queue_node(GFP_KERNEL, ...)
// Bỏ qua, chỉ return một request queue đã allocate nhưng chưa (hoàn toàn) construct
return blk_mq_init_allocated_queue(set, q)
q->mq_ops = set->ops
q->queue_ctx = alloc_percpu(...)
q->queue_hw_ctx = kcalloc_node(nr_cpu_ids)
// hwctx là array với element là pointer, length là số CPU
q->mq_map = set->mq_map
blk_mq_realloc_hw_ctxes(set, q)
// Ở đây thực tế allocate hctx instance
for-each(i, 0, set->nr_hw_queues)
// Chỉ cho empty hctxs[i]
hctxs[i] = kzalloc_node(...)
blk_mq_init_hctx(q, set, hctxs[i], alias hctx_idx = i)
hctx->queue = q
hctx->flag &= ~shared
hctx->tags = set->tags[hctx_idx]
hctx->ctxs = kmalloc_array_node(nr_cpu_ids, sizeof *)
hctx->nr_ctx = 0
set->ops->init_hctx(hctx, ...)
// Với nvme chủ yếu là thiết lập mối quan hệ giữa nvme_queue ở driver layer và hctx
blk_mq_sched_init_hctx(q, hctx, hctx_idx)
// Construct hctx->sched_tags
elevator e = q->elevator
blk_mq_sched_alloc_tags(q, hctx, hctx_id)
hctx->sched_tags = blk_mq_alloc_rq_map()
// Lặp lại, xem nvme flow, construct từng element instance của sched_tags[...]
blk_mq_alloc_rqs(set, hctx->sched_tags, ...)
// Lặp lại, xem nvme flow, liên quan đến static_rq
e->type->ops.mq.init_hctx(...)
// Tương tự, chỉ là chuyển thành sched_tag
hctx->fq = ...
blk_mq_init_request()
// Lặp lại, bỏ qua
// TODO: Ở đây sẽ có construct hctx của scheduling layer
q->nr_queues = nr_cpu_ids
blk_queue_make_request
// Đăng ký callback q->make_request_fn thành blk_mq_make_request
q->nr_batching = BLK_BATCH_REQ = 32
q->nr_request = set->queue_depth
blk_mq_init_cpu_queues(q, set->nr_hw_queues)
for-each cpu, i:
// Lấy percpu ctx
ctx->cpu = i
ctx->queue = q
...
blk_mq_add_queue_tag_set(set, q)
// Về cơ bản là liên kết q->tag_set = set
// và xử lý hctx trong shared mode, bỏ qua
blk_mq_map_swqueue(q)
// Xử lý mapping từ software queue đến hardware queue
for-each cpu, i:
hctx_id = q->mq_map[i]
// Lấy mapping ID từ CPU đến hctx từ map
hctx = q->queue_hw_ctx[q->mq_map[cpu]]
cpumask_set_cpu(i, hctx->cpumask)
ctx->index_hw = hctx->nr_ctx
hctx->ctxes[hctx->nr_ctx++] = ctx
// Một hctx có thể tương ứng với nhiều ctx, do đó dùng index_hw để biểu thị index của ctx trong hctx->ctxes[]
for-each hctx(q, hctx, i):
hctx->tags = set->tags[i]
...
elevator_init_mq(q)
// Chọn elevator mặc định
// Single queue chọn mq-deadline
// Multi queue hoặc không có mq-deadline thì chọn none
return q
5. Luồng IO của Framework
5.1. Luồng submit IO
Các thao tác IO từ userspace sẽ được mô tả bằng cấu trúc bio, và trong kernel sẽ được submit thông qua interface thống nhất submit_bio.
1
2
3
4
5
6
7
8
9
10
submit_bio(bio)
...
// IO accounting stuff
...
return generic_make_request_(bio)
q = bio->bi_disk->queue
...
// workaround for stacked devices
...
return q->make_request_fn(q, bio) ⭐
Từ luồng trước có thể biết, instance make_request_fn được đăng ký trong blk-mq là blk_mq_make_request.
1
2
3
4
5
6
blk_mq_init_allocated_queue()
...
blk_queue_make_request(q, blk_mq_make_request)
// set default blk-mq limits
q->make_request_fn = blk_mq_make_request
...
5.2. Luồng xử lý IO
Xử lý IO nói đơn giản là chuyển đổi bio thành cấu trúc request và insert vào request queue. So với submit IO được thực hiện trên kernel stack của process hiện tại, xử lý IO còn có thể được thực hiện async trong kernel thread kblockd.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
blk_mq_make_request(q, bio)
// Thực hiện bio split theo yêu cầu (thường theo giới hạn phần cứng/phần mềm)
// Merge vào plug queue của process theo yêu cầu, thành công thì kết thúc
// precondition: !FLUSH_FUA && !NOMERGE
blk_mq_sched_bio_merge
// Thử merge với pending request trong sched queue, thành công thì return
wbt_wait
// Khi vượt quá writeback limit, cung cấp blocking point tại đây
blk_mq_get_request
// Return một request, cần sử dụng kết hợp static_rqs và sbitmap
// note: merge theo yêu cầu ở trên không hoàn thành, do đó cần request
// Phân nhánh điều kiện:
// 1. flush or fua
// Cần dispatch nhanh chóng, bỏ qua scheduler, request insert vào flush queue riêng, wake up thực thi hctx
// 2. plug && q->nr_hw_queues == 1
// Single queue device và plug thì add vào mq_list của plug
// 3. plug && !no_merge
// Tương tự case2, nhưng đây là plug của multi-queue, bỏ qua
// 4. q->nr_hw_queues > 1 && sync
// Multi-queue, không có plug đi blk_mq_try_issue_directly
// Với read operation, nên áp dụng ở đây
// 5. others
// Đi blk_mq_sched_insert_request
// Ở đây sẽ tiếp tục phân chia trường hợp, ví dụ có flush hay không, có elevator hay không
// Nếu là case4:
// Trường hợp non-elevator, đi thẳng đến hàm enqueue do driver layer cung cấp
// Ngược lại, đi elevator sched_insert
// Nếu là case5:
// Trường hợp non-elevator, sẽ insert vào ctx queue
// Ngược lại, đi elevator sched_insert
// Còn cần xem setting run_queue, nếu có, tiếp theo blk_mq_run_hw_queue thực thi hctx để batch dispatch IO
// Thường thì run_queue = true, trừ khi driver layer thông báo hctx không khả dụng
Quá trình thực thi hctx (hw queue) blk_mq_run_hw_queue có thể là sync (đồng bộ) hoặc async (bất đồng bộ). Trong các điều kiện phân nhánh trên:
- Nếu là case4, thì là sync
- Nếu là case5, thì là async
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
blk_mq_run_hw_queue
__blk_mq_delay_run_hw_queue
__blk_mq_run_hw_queue
blk_mq_sched_dispatch_requests
// Đây là sync entry point
blk_mq_sched_dispatch_requests(hctx)
LIST_HEAD(rq_list)
if hctx->dispatch is not empty
list_splice_init(hctx->dispatch, rq_list)
// Trong hctx instance, dispatch field là request queue có ý nghĩa thực chất,
// bây giờ chuyển giao cho rq_list được allocate trên stack
// Chia thành vài trường hợp:
// 1. blk_mq_dispatch_rq_list
// Ưu tiên dispatch các request trước đó trong hctx chưa được dispatch đến driver
// 2. blk_mq_do_dispatch_sched
// Chuyển request trong sched queue vào rq_list, sau đó gọi blk_mq_dispatch_rq_list, dispatch đến driver
// 3. blk_mq_do_dispatch_ctx
// Trong trường hợp hctx busy, trực tiếp chuyển rq của ctx vào rq_list, sau đó dispatch cho driver
// Vì lý do công bằng, sẽ xem xét thực hiện dispatch luân phiên cho nhiều ctx
// 4. blk_mq_dispatch_rq_list
// Các trường hợp khác dispatch request trong rq_list cho driver xử lý
Quá trình này khá phức tạp, nhìn tổng thể là phân chia theo đặc điểm của IO:
- Thiết bị: Single queue hay multi-queue
- Hardware queue (hctx): Busy hay idle
- IO scheduler (elevator): Có attach vào blk-mq hay không
- Plug operation: Có enable plug hay không
- Request type: Sync hay async
Phân loại xử lý là dựa trên các đặc điểm trên để tổ hợp thành các nhánh path khác nhau:
- Có urgent không, urgent thì dispatch trực tiếp, flush->hctx
- Có phải slow device không, tức là single queue và plug
- Multi-queue plug
- IO scheduler attach, biểu thị mutual exclusive với ctx
- plug và nomerges và không attach, về cơ bản là ý nghĩa corner case của các điều kiện trước
- Có skip ctx không, tức là không có IO scheduler attach, device multi-queue, hctx idle và IO sync
- Default branch, trường hợp không có IO sched và không có plug
- Hidden branch, lần xử lý IO này thất bại, lần sau xử lý theo trường hợp urgent
Kết quả sau khi tổ hợp thường tuân theo thứ tự queue như sau:
1
2
-> flush ------------------------>
request -> [pluglist] -> [ctx || sched] -> hctx -> drivers/...
Một số ghi chú:
- IO scheduler queue và software queue là quan hệ mutual exclusive. IO scheduler attach vào blk-mq thì không sử dụng ctx
- plug là tùy chọn
- Khi hctx idle, một phần request có thể skip ctx và đi thẳng đến hctx (ví dụ path 6)
Theo kết quả phân tích của người đi trước (vì một số lý do, tôi không thể cung cấp reference link), các điều kiện sau áp dụng cho default path (7):
- IO request của EMMC device (high-speed không plug single queue)
- NVME device, async IO request
- NVME device, sync IO request, và hctx busy
Quay lại blk_mq_run_hw_queue, async flow sẽ có entry point hơi khác:
1
2
3
4
5
blk_mq_run_hw_queue
__blk_mq_delay_run_hw_queue
- __blk_mq_run_hw_queue
+ kblockd_mod_delayed_work_on
+ mod_delayed_work_on(cpu = hctx_next_cpu, kblockd_workqueue, dwork = hctx->run_work, delay = 0)
Task assignment được đăng ký trong initialization flow trước:
1
2
3
blk_mq_init_hctx
...
INIT_DELAYED_WORK(&hctx->run_work, blk_mq_run_work_fn)
Ở đây liên quan đến cơ chế workqueue, chú ý context sử dụng của nó:
- Thread instance:
kblockd - Task type:
delayed_worktype củahctx->run_work - Specific task:
run_worktương ứng vớiblk_mq_run_work_fn
1
2
3
blk_mq_run_work_fn(work)
hctx = container_of(work, ...)
__blk_mq_run_hw_queue(hctx)
Thực tế blk_mq_run_work_fn đi vòng quanh rồi lại quay về sync flow, chỉ khác là được giao cho kblockd xử lý.
6. Chi tiết không quan trọng
- Hardware queue của
blk-mqkhông liên quan đến queue ở driver layer. - Mặc dù software queue thường được coi là per-cpu level, nhưng maintainer cũng chỉ ra: nếu trong kiến trúc NUMA, L3 cache đủ lớn thì software queue có thể được thiết lập ở per-socket level, như vậy có thể đạt được điểm cân bằng giữa cache-friendly và lock contention.
- Số lượng hardware queue trong các trường hợp khác nhau có thể gây nhầm lẫn, vì kernel sẽ coi những hardware queue vượt quá số CPU là không tồn tại (do phần vượt quá không có ý nghĩa), nên không hoàn toàn bằng số hardware queue theo nghĩa phần cứng.
- Tag tuy được hardware queue sử dụng, nhưng độ dài thực tế của
blk_mq_tagsđược tính theo số CPU. - Số
requesttương ứng với tag tuy là số queue depth màsetcung cấp, nhưng mỗi lần allocation thất bại sẽ thử giảm queue depth một nửa, điều này cũng sẽ ảnh hưởng thực tế đếnset->queue_depth. - Mỗi instance
requestđược pre-allocate thực tế còn chứa payload mà driver layer cần. ns->queuechính là instancerequest_queue.- Trong quá trình submit IO,
generic_make_requestđã bị loại bỏ cùng với SQ framework, thay thế bằngblk_mq_submit_bio, nhưng bản chất không thay đổi. - Trong quá trình xử lý IO, case4 đi sync để chạy hctx là vì IO operation ban đầu đã là sync type.
- “Dispatch đến driver layer” có nghĩa là cuối cùng được gọi bởi interface
queue_rq, implementation cụ thể có liên quan mạnh với driver.
7. Một số khuyến nghị sử dụng
Q. Tôi sử dụng thiết bị single-queue truyền thống, có cần quay về single-queue framework không?
A. Không cần. Một là blk-mq trong thực tế vẫn có hiệu suất cao hơn sq framework, hai là từ kernel version 5.0 trở đi đã xóa hoàn toàn sq framework.
Q. Multi-queue framework có cần sử dụng IO scheduler không?
A. Nếu là HDD thì cần. Đối với SSD (đủ hiệu suất cao), ví dụ bạn cần fair scheduling hoặc làm QoS thì có thể dùng được, nhưng chỉ xét về hiệu suất thì đây là chủ đề mở (không phục thì chạy benchmark thôi).
Q. Nếu thực sự cần chọn IO scheduler, nên chọn như thế nào?
A. Tài liệu RedHat đưa ra một số lựa chọn theo scenario, để tiết kiệm IO của bạn, tôi tóm tắt các điểm chính:
| Use case | Disk scheduler |
|---|---|
| Traditional HDD với SCSI interface | Sử dụng mq-deadline hoặc bfq |
| High-performance SSD hoặc CPU-bound system với fast storage | Sử dụng none, đặc biệt khi chạy enterprise applications. Hoặc có thể dùng kyber |
| Desktop hoặc interactive tasks | Sử dụng bfq |
| Virtual guest | Sử dụng mq-deadline. Với HBA driver hỗ trợ multi-queue, dùng none |
Q. Các tùy chọn scheduler này quá naive, có tùy chọn tuning pro hơn không?
A. Tôi còn quá kém… Đây là một tài liệu RedHat khác có thể tham khảo.
8. TODO (Đã bỏ dở 🕊)
Không có gì bất ngờ khi lại bỏ dở khá nhiều nội dung:
- Luồng hoàn thành IO (liên quan đến interrupt).
- Hoàn thiện chi tiết luồng xử lý IO.
- Luồng merge, split IO.
- Cập nhật kernel version.
9. Tài liệu tham khảo
- Multi-Queue Block IO Queueing Mechanism (blk-mq) – The Linux Kernel Archives
- Linux Block IO: Introducing Multi-queue SSD Access on Multi-core Systems
- Chapter 11. Setting the disk scheduler – Red Hat Customer Portal
- Chapter 32. Factors affecting I/O and file system performance – Red Hat Customer Portal
- An Introduction to the Linux Kernel Block I/O Stack – IBM